اخبار کوانتومی – شبیه سازی کلاسیک با 1432 عدد GPU، برتری کوانتومی پردازنده کوانتومی سیکامور گوگل را به چالش کشید
عنوان خبر: شبیه سازی کلاسیک با 1432 عدد GPU، برتری کوانتومی پردازنده کوانتومی سیکامور گوگل را به چالش کشید
ژانر/موضوع: محاسبات کوانتومی
تاریخ انتشار خبر: 21 آوریل 2025
لینک خبر: scitechdaily.com
چکیده:
محققان مدار کوانتومی سیکامور گوگل، با 53 کیوبیت و 20 لایه را با استفاده از 1432 پردازنده گرافیکی NVIDIA A100 و الگوریتم های شبکه تانسور پیشرفته شبیه سازی کردند. روش آنها از استراتژی برش کارآمد و رویکرد نمونهگیری “top-k” برای کاهش شدید حافظه و تقاضاهای محاسباتی و در عین حال بهبود دقت استفاده میکند. این شبیهسازی نه تنها نمونههای نامرتبط با امتیاز XEB بالاتر را تولید کرد، بلکه 7 برابر سریعتر و با انرژی ۱۰۰ برابر کمتر از آزمایش اصلی گوگل اجرا شد. این نتایج که در مدارهای کوچکتر تأیید شده است، ادعای برتری کوانتومی گوگل در سال 2019 را به چالش میکشد. این کار معیار جدیدی را برای شبیهسازی کلاسیک تعیین کرده و نشان میدهد که حتی مدارهای کوانتومی در مقیاس بزرگ را میتوان به طور موثر با سختافزار کلاسیک شبیهسازی کرد. این پیشرفت، مرز مزیت محاسباتی کوانتومی را دوباره تعریف میکند.
شرح کامل خبر:
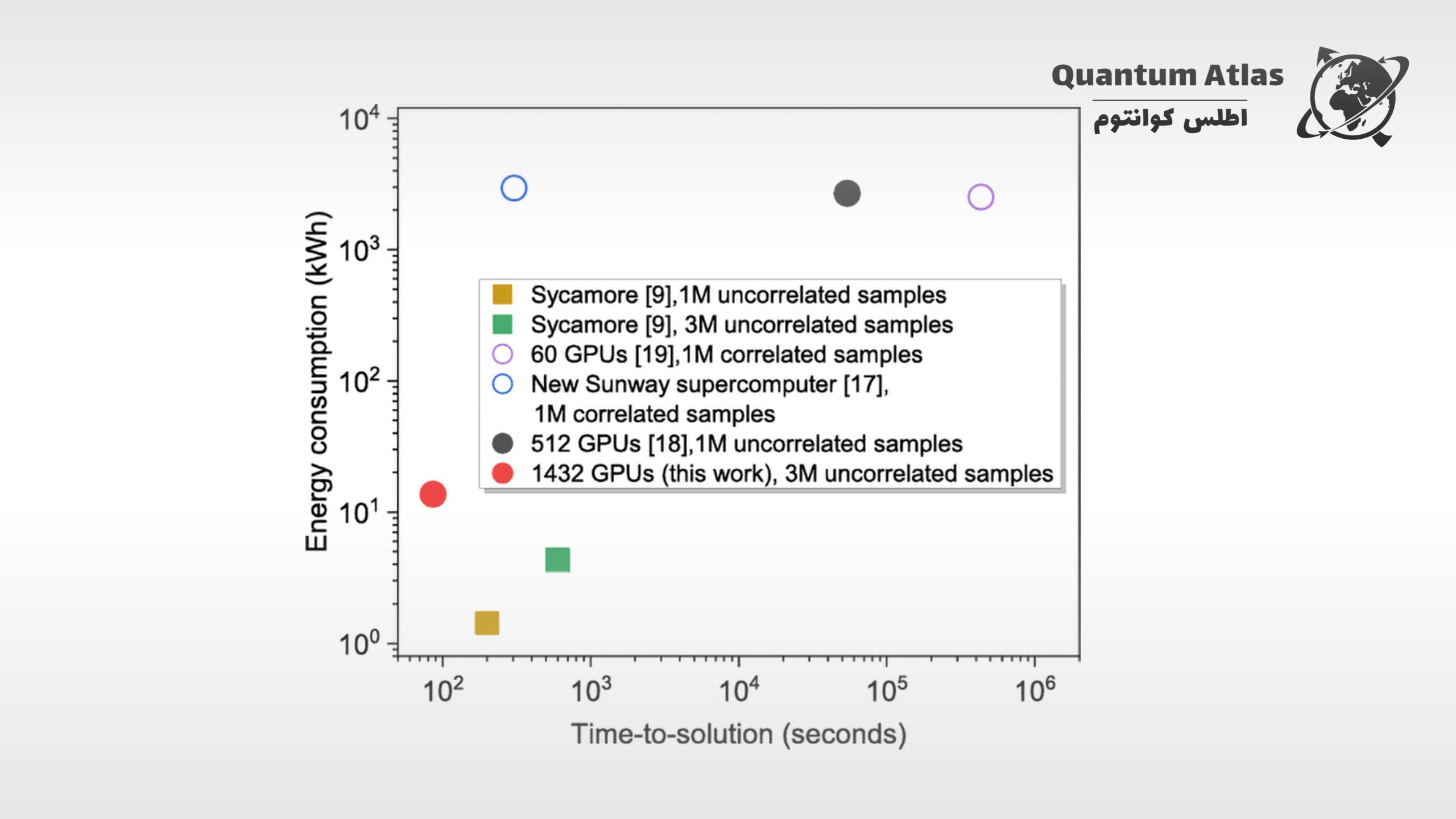
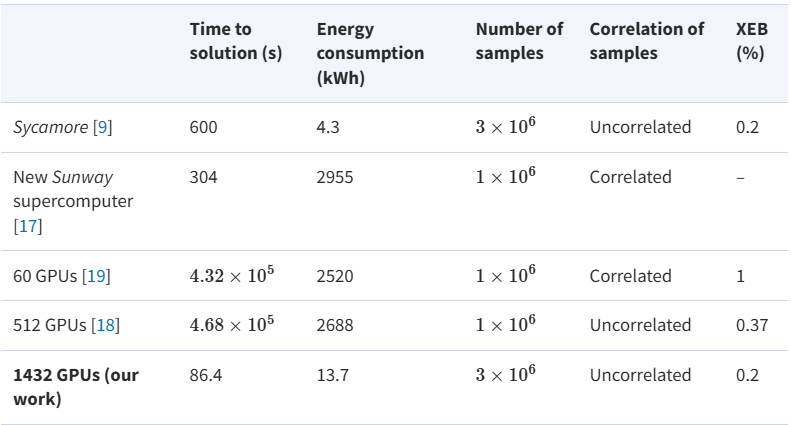
در یک دستاورد شگفتانگیز که مفاهیم پیشین دربارهی برتری کوانتومی را به چالش میکشد، تیمی از پژوهشگران توانستند شبیه سازی “نمونهبرداری مدار تصادفی کوانتومی” را که شرکت گوگل با کمک پردازنده ۵۳-کیوبیتی و ۲۰-لایهای Sycamore خود انجام داده بود، با استفاده از سختافزار کلاسیک شبیهسازی کنند—به طور خاص، با بهرهگیری از ۱۴۳۲ واحد پردازش گرافیکی (GPU) مدل NVIDIA A100 و همراه با تکنیکهای الگوریتمی پیشرفته. نتایج آنها نهتنها نمونههایی بدون همبستگی را سریعتر از پردازندهی کوانتومی Sycamore تولید میکند، بلکه از نظر بهرهوری انرژی و دقت نیز عملکرد بهتری دارد و بهطور مؤثری آستانهی مزیت محاسبات کوانتومی را بازتعریف میکند.
مزیت کوانتومی (یا “برتری کوانتومی”) به شرایطی گفته میشود که در آن یک رایانهی کوانتومی وظیفهای را انجام میدهد که برای رایانههای کلاسیک در بازهی زمانی معقولی غیرقابل انجام است. گوگل در سال ۲۰۱۹ مدعی دستیابی به این نقطهی عطف شد، زمانی که نشان داد پردازندهی Sycamore میتواند یک وظیفهی نمونهگیری از مدار تصادفی کوانتومی را در ۲۰۰ ثانیه انجام دهد—وظیفهای که گوگل تخمین زده بود رایانههای کلاسیک برای انجام آن به ۱۰٬۰۰۰ سال زمان نیاز دارند. با این حال، این ادعا با پیشرفتهای مستمر در تکنیکهای شبیهسازی کلاسیک، بهویژه از طریق الگوریتمهای مبتنی بر شبکههای تانسوری که از ساختار و درهمتنیدگی در مدارهای کوانتومی بهره میبرند، بهطور پیوسته تضعیف شده است.
در قلب این تلاش شبیهسازی جدید، روشهای بسیار بهینهشدهی انقباض شبکههای تانسوری (highly optimized tensor network contraction method) قرار دارد. این روشها توزیع خروجی مدار کوانتومی را از طریق تجزیه به زیرشبکههای کوچکتر و قابلمدیریت با استفاده از تکنیکهای برش، تقریب میزنند. این کار بهطور قابلتوجهی سربار حافظه را کاهش میدهد در حالی که کارایی محاسباتی حفظ میشود.
برای بهبود دقت نمونهگیری، پژوهشگران استراتژی نمونهگیری “top-k” را به کار گرفتند، که در آن تنها محتملترین رشتههای بیتی پردازش میشوند، بهجای تلاش برای نمونهگیری از کل فضای خروجی نمایی. این رویکرد موجب بهبود معیار Linear Cross-Entropy Benchmark (XEB) شد—معیاری که میزان تطابق خروجی شبیهسازی با توزیع احتمال کوانتومی مورد انتظار را اندازهگیری میکند.
این نوآوریها به سیستم کلاسیک اجازه دادند که نمونههای بدون همبستگی با امتیاز XEB بالاتر و با سرعتی هفت برابر سریعتر از آزمایش اصلی Sycamore تولید کند—نقطهعطفی مهم در عملکرد شبیهسازی.
برای اعتبارسنجی دقت و مقیاسپذیری الگوریتم خود، تیم پژوهشی آزمایشهای کنترلشدهای را بر روی مدارهای کوچکتر، نظیر مدار تصادفی ۳۰-کیوبیتی و ۱۴-لایهای انجام داد و نشان داد که نتایج شبیهسازی شده بهخوبی با پیشبینیهای نظری همخوانی دارند. موفقیت تکنیک نمونهگیری top-k در این آزمونها نقش آن را در بهبود فیدلیتی شبیهسازی بیشتر تقویت کرد.
علاوه بر نوآوریهای الگوریتمی، تیم پژوهشی دستاوردهای بزرگی در بهرهوری سختافزار کسب کرد. با بهینهسازی دقیق ترتیب ایندکسهای تانسور و کاهش ارتباطات میان GPUها، زمان محاسبات و مصرف انرژی بهطور چشمگیری کاهش یافت. استفاده از پیکربندیهایی با ۸ واحد حافظهی ۸۰ گیگابایتی در هر گره، امکان شبیهسازیهای توان بالا با سربار پایین را فراهم کرد و مصرف انرژی را تا دو مرتبهی بزرگی کمتر از تلاشهای کلاسیک پیشین رساند.
علاوه بر این، تحلیل پیچیدگی نشان داد که افزایش حافظه از ۸۰ گیگابایت به حتی ۵۱۲۰ گیگابایت در هر گره میتواند پیچیدگی زمانی را بیشتر کاهش دهد، که چشمانداز آیندهای قدرتمندتر با پیشرفت حافظه و سختافزار را نوید میدهد.
پژوهشگران ادعا میکنند که این کار، نخستین ردّ تجربیِ بدون ابهامِ ادعای اولیهی Sycamore در زمینهی مزیت کوانتومی است. توانایی شبیهسازی کارآمد یک مدار کوانتومی ۵۳-کیوبیتی و ۲۰-لایهای با استفاده از سختافزار کلاسیک—در حالی که نمونههایی بدون همبستگی و با عملکرد بهتر تولید میکند—مرز میان رژیمهای محاسباتی کلاسیک و کوانتومی را زیر سؤال میبرد.
این مطالعه نهتنها معیار شبیهپذیری کلاسیک برای مدارهای کوانتومی را بازتعریف میکند، بلکه چارچوبی قدرتمند برای کارهای آینده در زمینهی اعتبارسنجی الگوریتمهای کوانتومی و بهینهسازی سختافزار کلاسیک برای شبیهسازی کوانتومی فراهم میسازد.
با ادغام تکنیکهای پیشرفتهی تانسوری، استراتژیهای هوشمندانهی نمونهگیری، و محاسبات کلاسیک با عملکرد بالا، این دستاورد زمینهساز درک دقیقتر و ظریفتری از مزیت محاسباتی کوانتومی شده است. با ادامهی پیشرفت الگوریتمهای کلاسیک و بهبود سختافزار، رقابت برای دستیابی به برتری عملی کوانتومی نیازمند بازبینی مداوم خواهد بود—تلاشی برای برقراری تعادل میان جهشهای واقعی کوانتومی و تابآوری کلاسیک.
منابع:
[1] https://scitechdaily.com/how-1432-gpus-cracked-googles-53-qubit-quantum-computer/
[2] https://academic.oup.com/nsr/article/12/3/nwae317/7756427?login=false
دیدگاه خود را درباره این خبر با ما به اشتراک بگذارید.