
محققان MIT پیشرفت قابل توجهی در زمینه تصحیح خطای کوانتومی داشته اند و روش جدیدی به نام تصحیح خطای کوانتومی خودکار (AQEC) را پیشنهاد کرده اند. هدف AQEC حفاظت از کیوبیت های منطقی بدون نیاز به حلقه های اندازه گیری-فیدبک مکرر، و در نتیجه کاهش خطاها و بهبود پایداری سیستم های کوانتومی است.
این تیم بر روی فضاهای کد بوزونی تمرکز کردند که به دلیل انعطاف پذیری و کنترل پذیری خود شناخته شده اند. در این فضاها، از دست دادن تک فوتون منبع اصلی خطا است. پیشنهادهای موجود AQEC، بر اجرای دقیق شرایط Knill-Laflamme تکیه کردهاند که به فاصلههای همیلتونی (d) حداقل 2 نیاز دارد.
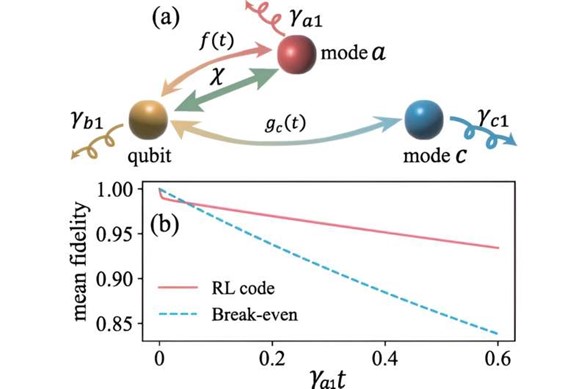
برای غلبه بر این چالش ها، محققان MIT از reinforcement learning (RL) برای شناسایی مجموعه ای از کلمات کد بهینه، به نام کد RL استفاده کردند. با کمال تعجب، کد RL از حالت های Fock states دو و چهار تشکیل شده است. اگرچه کد RL یک راه حل تقریبی است، اما به طور موثری از دست دادن تک فوتون را کاهش می دهد و آن را به یک فرآیند کاهش فاز کارآمد می رساند که از آستانه سربه سر فراتر می رود.
همیلتونین تصحیح کننده خطای پیشنهادی، که شامل سیستمهای ancilla برای شبیهسازی اتلاف مهندسی شده میباشد، بر اساس فاصله همیلتونی d=1 است که پیچیدگی مدل را بهطور قابلتوجهی کاهش میدهد. علاوه بر این، گیت های تک کیوبیتی را می توان در کد RL با حداکثر فاصله dg=2 پیاده سازی کرد که فرآیند پیاده سازی را بیشتر ساده می کند.
با آرام کردن الزامات سختگیرانه شرایط Knill-Laflamme و استفاده از بهینه سازی RL، تیم امکان سنجی AQEC را با فضاهای کد بوزونی نشان داده است. کد RL به طور موثری از دست دادن تک فوتون را سرکوب می کند و سیستم های کوانتومی را قادر می سازد از آستانه سربه سر فراتر رفته و محافظت از خطا را بهبود بخشد.
این یافته ها پیامدهای مهمی برای حوزه محاسبات کوانتومی و توسعه سیستم های کوانتومی قابل اعتماد دارند. AQEC یک رویکرد امیدوارکننده برای محافظت از کیوبیت های منطقی، کاهش خطاها و بهبود پایداری کلی سیستم های کوانتومی ارائه می دهد. با کد RL پیشنهادی و همیلتونین تصحیح کننده خطا، پیچیدگی اجرای AQEC تا حد زیادی کاهش می یابد و آن را برای تحقق تجربی عملی تر می کند.
تحقیقات بیشتر بر کاوش منابع اضافی خطا و بهینهسازی کد RL برای قابلیتهای حتی بیشتر از بین بردن خطا متمرکز خواهد بود. هدف نهایی دستیابی به حفاظت کامل از خطا در سیستمهای کوانتومی است که ما را به توسعه فناوریهای کوانتومی قوی و قابل اعتماد نزدیکتر میکند که میتواند زمینههای مختلف از جمله رمزگذاری، شبیهسازی و بهینهسازی را متحول کند.
منبع
Yexiong Zeng et al, Approximate Autonomous Quantum Error Correction with Reinforcement Learning, Physical Review Letters (2023). DOI: 10.1103/PhysRevLett.131.050601










